I was reading an article recently regarding Storage provisioning, the article was titled “The Right Way to Provision Storage”. What I took away from the article, as reader, is that storage provisioning is a painful, time consuming process involving several people representing different groups.
The process according to the article pretty much goes like this:
Step 1: DBA determines performance requirement and number of LUNs and defers to the Storage person
Step 2: Storage person creates the LUN(s) and defers to the Operations person
Step 3: Operations person maps the LUN(s) to some initiator(s) and defers to the Server Admin
Step 4: Server Admin discovers the LUN(s) and creates the Filesystem(s). Then he/she informs the DBA, probably 3-4 days later, that his/her LUN(s) are ready to host the application
I wonder how many requests per week these folks get for storage provisioning and how much of their time it consumes. I would guess, much more than they would like. An IT director of a very large and well know Financial institution, a couple of years ago, told me “We get over a 400 storage provisioning requests a week and it has become very difficult to satisfy them all in a timely manner”.
Why does storage provisioning have to be so painful? It seems to me that one would get more joy out of getting a root canal than asking for storage to be provisioned. Storage provisioning should be a straight forward process and the folks who own the data (Application Admins) should be directly involved in the process.
In fact, they should be the ones doing the provisioning directly from the host under the watchful eye of the Storage group who will control the process by putting the necessary controls in place at the storage layer restricting the amount of storage Application admins can provision and the operations they are allowed to perform. This would be self-service storage provisioning and data management.
Dave Hitz on his blog, a few months back, described the above process and used the ATM analogy as example.
NetApp’s SnapDrive for Unix (Solaris/AIX/HP-UX/Linux) is similar to an ATM. It lets data application admins manage and provision storage for the data they own. Thru deep integration with various Logical Volume Managers, filesystem specific alls, SnapDrive for Unix allows administrators to do the following with a single host command:
1) Create LUNs on the array
2) Map the LUNs to host initiators
3) Discover the LUNs on the host
4) Create Disk Groups/Volume Groups
5) Create Logical Volumes
6) Create Filesystems
7) Add LUNs to Disk Group
8) Resize Storage
9) Create and Manage Snapshots
10) Recover from Snapshots
11) Connect to filesystems in Snapshots and mount them onto the same or a different Host the original filesystem was or still is mounted
The whole process is fast and more importantly very efficient. Furthermore, it masks the complexity of the various UNIX Logical Volume Managers and allows folks who are not intimately familiar with them to successfully perform various storage related tasks.
Additionally, SnapDrive for Unix provides snapshot consistency by making calls to filesystem specific freeze/thaw mechanisms providing image consistenty and the ability to successfully recover from a Snapshot.
Taking this a step further, SnapDrive for Unix provides the necessary controls at the storage layer and allows Storage administrators to specify who has access to what. For example, an administrator can specify any or a combination of the following access methods.
◆ NONE − The host has no access to the storage system.
◆ CREATE SNAP − The host can create snapshots.
◆ SNAP USE − The host can delete and rename snapshots.
◆ SNAP ALL− The host can create, restore, delete, and rename
snapshots.
◆ STORAGE CREATE DELETE − The host can create, resize,
and delete storage.
◆ STORAGE USE − The host can connect and disconnect storage.
◆ STORAGE ALL − The host can create, delete, connect, and
disconnect storage.
◆ ALL ACCESS− The host has access to all the SnapDrive for
UNIX operations.
Furthermore, SnapDrive for Unix is tightly integrated with NetApp’s SnapManager for Oracle product on several Unix platforms which allows application admins to manage Oracle specific Datasets. Currently, SnapDrive for Unix supports Fibre Channel, iSCSI and NFS.
SnapDrive for Unix uses HTTP/HTTPs as a transport protocol with password encryption and makes calls to DataONTAP’s APIs for storage management related tasks.
There’s also a widely deployed Windows version of SnapDrive that integrates with Microsoft’s Logical Disk Manager/NTFS and VSS and allows admins to perform similar tasks. Furthermore, SnapDrive for Windows is tightly integrated with NetApp’s SnapManager for Exchange and SnapManager for SQL products that allow administrators to obtain instantaneous backups and near-instantaneous restores of their Exchange or SQL server database(s).
Below are a couple of examples from my lab server of using SnapDrive for Unix of what it takes to provision Storage on a Solaris host with Veritas Foundation Suite installed.
Example 1:
In this example I’m creating 2 LUNs of 2GB size each on controller named filer-a on volume named /vol/boot.
The LUNs are named lun1 and lun2. I then create a Veritas disk group named dg1. On that disk group I create a Veritas volume named testvol. On volume testvol, I then create a filesystem with /test as the mount point. By default and unless instructed otherwise via a nopersist option, SnapDrive will also make an entries into the Solaris /etc/vfstab file.
The following is what the filesystem looks like and Veritas sees immidiately after the above process has completed:
Example 2:
Below, I obtain a snapshot of the Veritas filesystem and name the snapshot test_snap. I then make an inquiry to the array to obtain a list of consistent snapshots for my /test filesystem.
This reveals that I have taken 3 different snapshots at different points in time and I can recover from anyone of them. I can also connect to any one of them and mount the filesystem.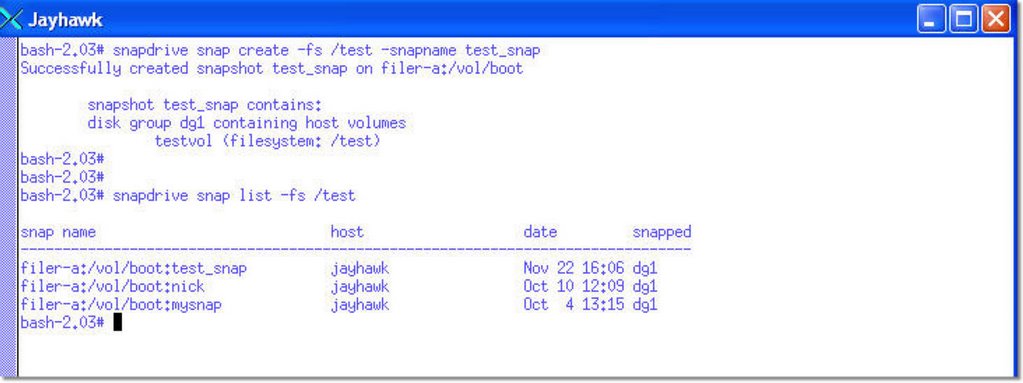
Example 3
Here I'm connecting to the filesystem from the most recent snapshot, test_snap, and i'm mounting a space optimized clone of the original filesystem at the time the snapshot was taken. Ultimately, I will end up with 2 copies of the filesystem.

The original one, named /test, and the one from the snapshot which I will rename /test_copy. Both of the filesystems are mounted on the same Solaris server (they don't have to be) and are under Veritas Volume Manager control.
This is how simple and easy it is to provision and manage storage using NetApp's SnapDrive. Franky, it seems to be that a lengthy process explaining the "proper" way to provision storage adds extra layers of human intervention, uncessary complexity, it's inefficient and time consuming.